
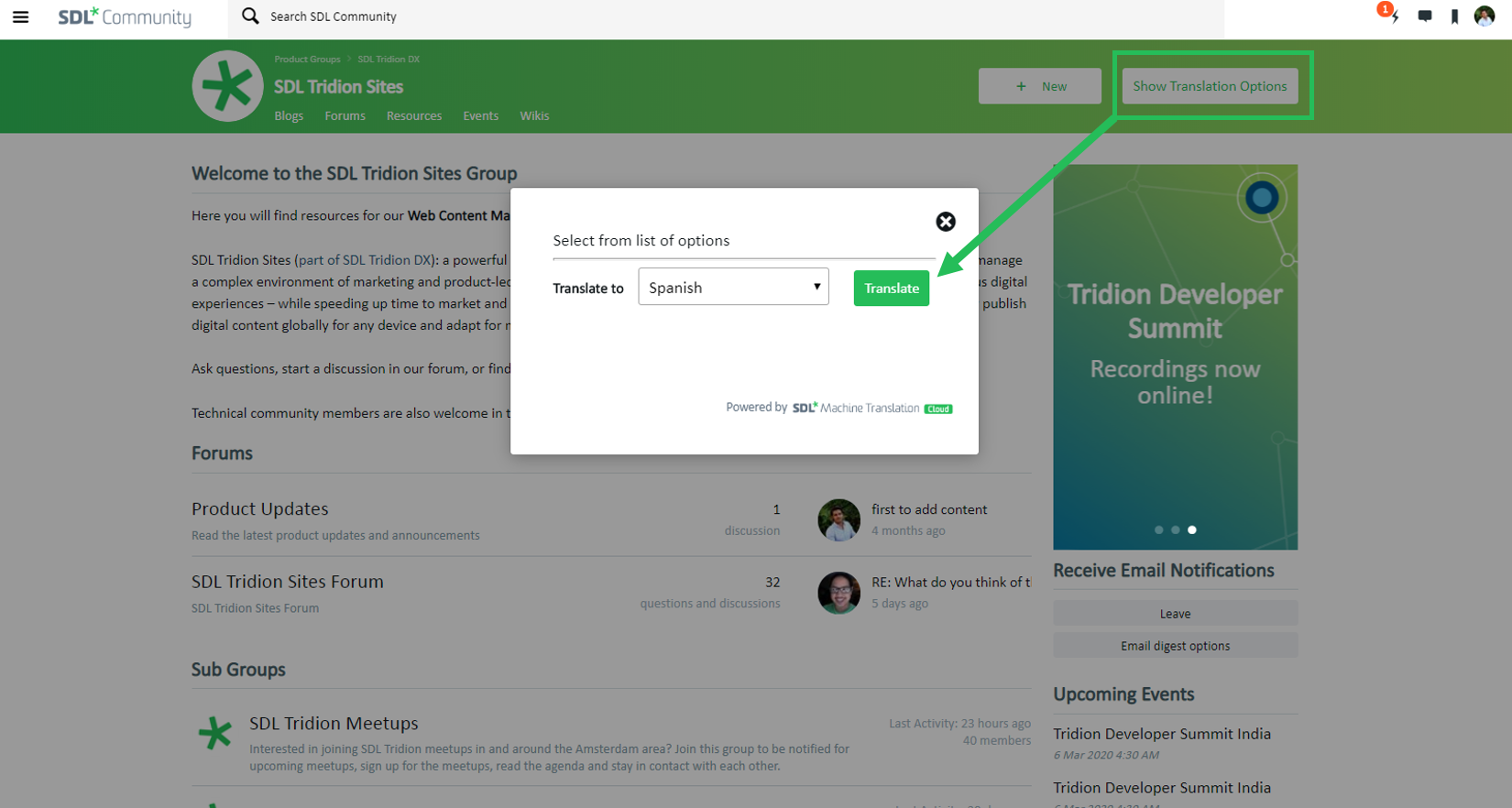
机器翻译(Machine translation,MT)已经成为语言和翻译界一个非常重要的话题。越来越多的公司已经开始应用机器翻译,因为它可以使他们的翻译项目受益。但机器翻译到底是什么,存在哪些不同的类型?这些是我将在下一篇文章中更仔细研究的要点。
根据定义,机器翻译是一种计算语言学和语言工程的形式,它使用软件将文本或语音从一种语言翻译到另一种语言。基本上,在机器翻译过程中,一个源语言单词被目标语言中的一个单词所代替。但不要把机器翻译与计算机辅助翻译(CAT)混淆,后者是指人工翻译人员使用计算机软件辅助翻译过程;CAT工具不会自动翻译内容。
有几种机器翻译引擎可以对内容进行不同的分析和处理。最常见的是基于规则的机器翻译和统计机器翻译。
基于规则的机器翻译(RBMT)
基于规则的引擎使用无数的语法和语言规则来分析内容和分解文本。在使用这些规则时,源语言的语法结构被转换成目标语言。双语词典也用于语言对,可以添加自定义术语列表来微调引擎。通过在特定主题或行业中添加特定术语,可以在特定主题上创建更可靠的翻译结果。基于规则的引擎不需要双语语料库(也称为大型结构化文本集)来创建翻译系统。
基于规则的引擎由于翻译所基于的语法规则和词典的数量,产生了相当可预测的,但也非常一致的输出。由于设置了规则,每个错误都可以用目标规则来纠正。因此,通过添加更多的规则和更多的词典或术语,可以改进翻译。
统计机器翻译(SMT)
与RBMT不同,统计机器翻译不基于语言规则分析文本。相反,这个引擎“学习”如何翻译文本。因此,它分析语言对中的大量数据,然后使用其统计翻译模型来创建源内容的翻译。该模型是通过分析双语语料库建立起来的,需要适当的双语内容量。使用SMT,还可以通过提供与所讨论主题相关的更多数据来关注特定主题或行业。
机器翻译与神经网络
机器翻译正在发展。自2013年以来,谷歌和微软等互联网巨头一直在探索使用神经网络的可能性。神经网络是最早应用于语音和图像识别技术的统计学习模型。在机器翻译中使用它们使引擎能够通过模式和结构训练自己如何使用类似于人脑工作方式的过程翻译文本。这个过程被称为“深度学习”,它基于通过实施大数据分析而确立的原则。
虽然神经机器翻译(NMT)是一种新的翻译方法,但它被认为是一个巨大的突破,并且已经在机器翻译研究者中非常流行,因为很明显,它在大多数情况下提高了翻译,提供的输出看起来更流畅,更人性化。
他们说,NMT可以创造更流畅的翻译,并且可以减少多达25%的后期编辑工作。对于一些语言专业人士来说,毫无疑问,神经机器翻译比基于规则或统计的机器翻译表现得更好。NMT系统能够理解和看到单词的相似性,考虑整个句子,学习语言之间的复杂关系(来源:神经翻译是一个突破的三个原因)。
由于每个引擎处理和生成数据的方式不同,因此为项目选择的引擎取决于目标语言和给定源文件的参考资料的可用性。一般来说,机器翻译最适合重复性和简单性的内容,在这些内容中,相同的词被重用,同义词被最小化。毫无疑问,机器翻译的优势在于:它提高了生产率,缩短了上市时间,提高了术语的一致性。


{kind=link}
已经成为语言和翻译界一个非常重要的话题。越来越多的公司已经开始应用机器翻译,因为它可以使他们的翻译项目受益。但机器翻译到底是什么,存在哪些不同的类型?这些是我将在下一篇文章中更仔细研究的要点。 根据定义,机器翻译是一种计算语言学和语言工程的形式,它使用软件将文本或语音从一种语言翻译到另一种语言。基本上,在机器翻译过程中,一个源语言单词被目标语言中的一个单词所代替。但不要把机器翻译与计算机辅助翻译(CAT)混淆,后者是指人工翻译人员使用计算机软件辅助翻译过程;CAT工具不会自动翻译内容。 有几种机器翻译引擎可以对内容进行不同的分析和处理。最常见的是基于规则的机器翻译和统计机器翻译。 基于规则的机器翻译(RBMT) 基于规则的引擎使用无数的语法和语言规则来分析内容和分解文本。在使用这些规则时,源语言的语法结构被转换成目标语言。双语词典也用于语言对,可以添加自定义术语列表来微调引擎。通过在特定主题或行业中添加特定术语,可以在特定主题上创建更可靠的翻译结果。基于规则的引擎不需要双语语料库(也称为大型结构化文本集)来创建翻译系统。 基于规则的引擎由于翻译所基于的语法规则和词典的数量,产生了相当可预测的,但也非常一致的输出。由于设置了规则,每个错误都可以用目标规则来纠正。因此,通过添加更多的规则和更多的词典或术语,可以改进翻译。 统计机器翻译(SMT) 与RBMT不同,统计机器翻译不基于语言规则分析文本。相反,这个引擎“学习”如何翻译文本。因此,它分析语言对中的大量数据,然后使用其统计翻译模型来创建源内容的翻译。该模型是通过分析双语语料库建立起来的,需要适当的双语内容量。使用SMT,还可以通过提供与所讨论主题相关的更多数据来关注特定主题或行业。 机器翻译与神经网络 机器翻译正在发展。自2013年以来,谷歌和微软等互联网巨头一直在探索使用神经网络的可能性。神经网络是最早应用于语音和图像识别技术的统计学习模型。在机器翻译中使用它们使引擎能够通过模式和结构训练自己如何使用类似于人脑工作方式的过程翻译文本。这个过程被称为“深度学习”,它基于通过实施大数据分析而确立的原则。 虽然神经机器翻译(NMT)是一种新的翻译方法,但它被认为是一个巨大的突破,并且已经在机器翻译研究者中非常流行,因为很明显,它在大多数情况下提高了翻译,提供的输出看起来更流畅,更人性化。 他们说,NMT可以创造更流畅的翻译,并且可以减少多达25%的后期编辑工作。对于一些语言专业人士来说,毫无疑问,神经机器翻译比基于规则或统计的机器翻译表现得更好。NMT系统能够理解和看到单词的相似性,考虑整个句子,学习语言之间的复杂关系(来源:神经翻译是一个突破的三个原因)。 由于每个引擎处理和生成数据的方式不同,因此为项目选择的引擎取决于目标语言和给定源文件的参考资料的可用性。一般来说,机器翻译最适合重复性和简单性的内容,在这些内容中,相同的词被重用,同义词被最小化。毫无疑问,机器翻译的优势在于:它提高了生产率,缩短了上市时间,提高了术语的一致性。&url=https%3A%2F%2Fwww.landeservice.cn%2Farchives%2F29567.html&pics=https://landeservice.oss-cn-shanghai.aliyuncs.com/wp-content/uploads/2020/03/mt1.1.png){kind=link}